人工智能安全|AI安全應(yīng)用:基于代碼語(yǔ)義的惡意代碼同源分析



1.引言
我們?cè)谇拔闹兄攸c(diǎn)介紹了基于圖像分類的惡意代碼同源分析方法,該方法本質(zhì)上是根據(jù)惡意代碼字節(jié)流內(nèi)容的特征進(jìn)行分類。然而,這種方法從逆向工程的角度來(lái)看不具有可解釋性。
眾所周知,匯編代碼具有較為鮮明的語(yǔ)法可讀性。如果先把惡意代碼進(jìn)行反匯編,然后用自然語(yǔ)言處理(Natural Language Processing)技術(shù)提取代碼語(yǔ)義特征,再進(jìn)行同源分析,這樣的方法就容易解釋,這就是本文將介紹的基于代碼語(yǔ)義的同源分析方法。當(dāng)前,這種方法不僅被用于惡意代碼檢測(cè)領(lǐng)域,還被用在代碼克隆搜索、代碼侵權(quán)判定等領(lǐng)域。
本文首先介紹了基于代碼語(yǔ)義同源分析的基礎(chǔ)知識(shí);其次介紹了基于代碼語(yǔ)義的同源分析相關(guān)工作;最后,給出了基于代碼語(yǔ)義的同源分析技術(shù)方案設(shè)計(jì),并通過(guò)實(shí)驗(yàn)驗(yàn)證了方案的有效性。
2.基礎(chǔ)知識(shí)
基于代碼語(yǔ)義的惡意代碼同源分析的基礎(chǔ)是語(yǔ)義提取。PV-DM和TextCNN是NLP領(lǐng)域有關(guān)代碼語(yǔ)義提取的兩種常見(jiàn)的模型, 說(shuō)明如下:
(1)句向量的分布式記憶模型(Distributed Memory Model of Paragraph Vectors,PV-DM)
在PV-DM模型中,詞向量和句向量相拼接,用來(lái)預(yù)測(cè)文本中的下一個(gè)詞,通過(guò)在句子上的窗口滑動(dòng),使句向量記憶句子中所有詞的上下文關(guān)系。在代碼語(yǔ)義提取中使用PV-DM模型,能簡(jiǎn)單有效地解決向量長(zhǎng)度不一致問(wèn)題(圖1).
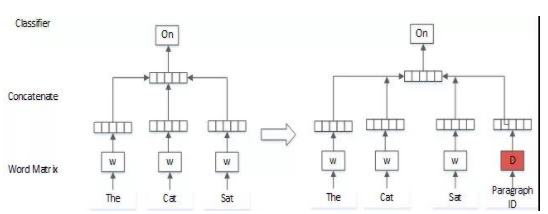
圖1 PV-DM模型
(2)TextCNN模型
TextCNN通過(guò)拼接詞向量將文本轉(zhuǎn)化成矩陣,然后應(yīng)用卷積神經(jīng)網(wǎng)絡(luò)發(fā)揮深度學(xué)習(xí)的優(yōu)勢(shì)。相比于一般的卷積神經(jīng)網(wǎng)絡(luò)模型,TextCNN在卷積層中應(yīng)用多個(gè)不同尺寸的卷積核(圖2)。TextCNN具有網(wǎng)絡(luò)結(jié)構(gòu)簡(jiǎn)單、訓(xùn)練速度快并且效果較好等優(yōu)點(diǎn)。但是,在嵌入層中采用預(yù)訓(xùn)練的詞向量模型(如Word2Vec)進(jìn)行語(yǔ)義提取,因而會(huì)有長(zhǎng)度不一致的問(wèn)題。
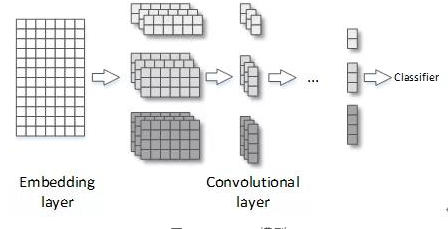
圖2 TextCNN模型
3.相關(guān)工作
Zhang等[2]圍繞勒索軟件的家族分類問(wèn)題,提出一種特征提取方法,該方法將樣本指令序列轉(zhuǎn)換為不同n值時(shí)的n-gram集合,計(jì)算每個(gè)n-gram的TF-IDF(term frequency–inverse document frequency)并選擇家族中TF-IDF值較高的t個(gè)n-gram作為特征。然而,n-gram特征僅僅反映序列化特征,不能提取代碼文本的語(yǔ)義信息。
陳等提出一種基于代碼語(yǔ)義的惡意代碼同源判定方法[3],利用Word2Vec獲取指令的詞向量,并利用TextCNN進(jìn)行分類。Fang等人則采用了FastText模型提取JavaScript代碼的詞向量[4],F(xiàn)astText將多個(gè)單詞及其n-gram作為輸入,直接輸出模型判定的類別。
Ding等提出一種匯編代碼的語(yǔ)義模型-Asm2Vec[5],用于提取指令代碼的語(yǔ)義信息。該方法基于句向量的分布式記憶模型PV-DM設(shè)計(jì),并考慮了匯編代碼格式的適應(yīng)性問(wèn)題。由于控制流程圖能在一定程度上反映代碼的動(dòng)態(tài)順序信息,一些研究工作先構(gòu)建代碼的控制流程圖,再利用圖匹配、圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Network,GNN)等技術(shù)評(píng)估代碼相似性。GNN雖然性能比傳統(tǒng)的圖匹配更好,但在語(yǔ)義學(xué)習(xí)上仍有不足。為此,Yu等提出一種同時(shí)捕捉代碼的語(yǔ)義、結(jié)構(gòu)以及順序的方法[6],利用Bert模型進(jìn)行預(yù)測(cè)訓(xùn)練以獲取語(yǔ)義信息,利用消息傳遞神經(jīng)網(wǎng)絡(luò)(Message Passing NeuralNetwork,MPNN)獲取結(jié)構(gòu)信息,利用Resnet模型提取順序信息。
4.方案設(shè)計(jì)
基于代碼語(yǔ)義的同源分析方案主要由語(yǔ)義特征提取和同源分類訓(xùn)練兩大部分構(gòu)成。具體處理流程上,主要包括了如下步驟(圖3)
第一步:數(shù)據(jù)準(zhǔn)備。收集樣本并標(biāo)注類別,構(gòu)建訓(xùn)練數(shù)據(jù)集;
第二步:反匯編。對(duì)可移植可執(zhí)行的惡意代碼文件進(jìn)行反匯編,獲得匯編代碼;
第三步:預(yù)處理。利用NLP技術(shù)對(duì)匯編進(jìn)行分詞、關(guān)鍵詞篩選等預(yù)處理;
第四步:語(yǔ)義提取。構(gòu)建語(yǔ)義模型,使用訓(xùn)練數(shù)據(jù)進(jìn)行訓(xùn)練,并提取出每個(gè)樣本的語(yǔ)義特征。本文使用了PV-DM以及TextCNN中的Word2Vec作為語(yǔ)義提取模型。
第五步:同源分類。根據(jù)語(yǔ)義特征,采用相似性度量或聚類/分類算法分析同源性。本文使用了DNN、KMeans聚類、CNN等技術(shù)。
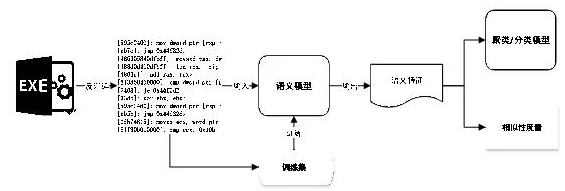
圖3 基于代碼語(yǔ)義的同源分析流程
5.實(shí)驗(yàn)分析
本節(jié)通過(guò)實(shí)驗(yàn)驗(yàn)證兩種基于代碼語(yǔ)義模型的同源分析方法。實(shí)驗(yàn)所用樣本來(lái)源于網(wǎng)絡(luò),包括Application、Backdoor、Generic、Trojan、Variant、Virus及Worm等類別(表1)。
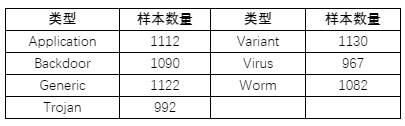
表1. 實(shí)驗(yàn)數(shù)據(jù)集
實(shí)驗(yàn)一:基于PV-DM模型的同源分析
圖4為PV-DM語(yǔ)義模型的訓(xùn)練過(guò)程。提取出256維的語(yǔ)義向量,應(yīng)用神經(jīng)網(wǎng)絡(luò)進(jìn)行分類,按照比例4:1劃分訓(xùn)練集和測(cè)試集,總體準(zhǔn)確率為0.74。另外,對(duì)提取的語(yǔ)義特征采用KMeans算法進(jìn)行了聚類,測(cè)試準(zhǔn)確率同樣是0.74。

圖4 基于 PV-DM的DNN模型訓(xùn)練及測(cè)試
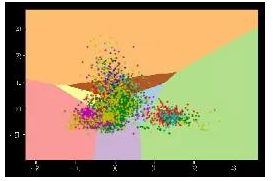
圖5 基于PV-DM的KMeans聚類(Accuracy=0.74)
實(shí)驗(yàn)二:基于TextCNN的同源分析
圖6為樣本中指令數(shù)量的統(tǒng)計(jì),平均指令數(shù)量為28,最小為1(195個(gè)樣本),最大為74(1個(gè)樣本)。構(gòu)建TextCNN模型,設(shè)置不同大小的一維卷積核,將特征圖最大池化并拼接,將數(shù)據(jù)集按照比例4:1劃分為訓(xùn)練集和驗(yàn)證集,如圖7所示,測(cè)試準(zhǔn)確率為0.65左右。

圖6 指令數(shù)量統(tǒng)計(jì)
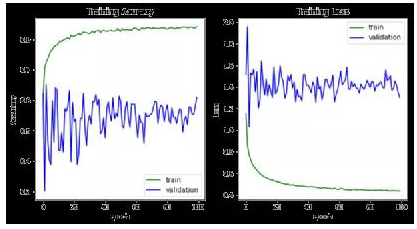
圖7 TextCNN訓(xùn)練及測(cè)試
6.總結(jié)
本文通過(guò)實(shí)驗(yàn)證明了基于代碼語(yǔ)義的惡意代碼同源分析方法具備一定的可行性。然而,PV-DM、TextCNN方法直接應(yīng)用于提取匯編代碼語(yǔ)義時(shí),完全將匯編代碼類比成純文本,語(yǔ)義提取的準(zhǔn)確性略低。文獻(xiàn)[5]是針對(duì)匯編代碼而設(shè)計(jì)的語(yǔ)義提取方法,能夠更加精確地提取語(yǔ)義信息,后續(xù)將圍繞此方法作進(jìn)一步研究。
參考文獻(xiàn)
[1]智能安全研究組 人工智能安全|AI安全應(yīng)用|基于圖像分類的同源分析. 2021.10.15
[2]Hanqi Zhang, Xi Xiao.Classification of ransome families with machine learning based on N-gram ofopcodes[J]. Future generation computer system, 2019(90):211-221.
[3]陳涵泊,吳越,鄒福泰 . 基于 Asm2Vec 的惡意代碼同源判定方法 [J]. 通信技術(shù) ,2019,52(12):3010-3015.
[4]Yong Fang, Cheng Huang.Detecting malicious JavaScript code based on semantic analysis[J].Computer&Security, 2020(93):1-9.
[5]Steven H H Ding, Benjamin C MFung. Asm2Vec: Boosting Static Representation Robustness for Binary CloneSearch against Code Obfuscation and Compiler Optimization[C]. S&P,2019:1-18.
[6]Zeping Yu, Rui Cao, Qiyi Tang,et al. Order Matters:Semantic-Aware Neural Networks forBinary Code Similarity Detection[C]. AAAI, 2020:1-8.
版權(quán)聲明
轉(zhuǎn)載請(qǐng)務(wù)必注明出處。
版權(quán)所有,違者必究。
- 關(guān)鍵詞標(biāo)簽:
- 天融信 人工智能安全 AI安全應(yīng)用

